
Tipos de aprendizaje automático
26 mayo 2018Como vimos en el primer post, el aprendizaje automático o machine learning consiste en un conjunto de algoritmos que aprenden y resuelven problemas gracias a la experiencia. Hay diversos tipos de problemas que se abordan con técnicas de machine learning, entre ellos se encuentran los problemas de clasificación (donde queremos predecir una clase), los de regresión, las series temporales, etc. De estos problemas típicos también hice una pequeña introducción aquí. En este post trataré los distintos tipos de aprendizaje que usan los algoritmos de machine learning.
Los algoritmos de aprendizaje automático pueden aprender de 4 formas distintas: mediante un aprendizaje supervisado, con aprendizaje no supervisado, con aprendizaje semisupervisado o con aprendizaje por refuerzo.
Los 3 primeros tipos de algoritmos se diferencian en el conocimiento a priori que se tiene en cada uno. Los dos extremos son el supervisado, donde se tiene conocimiento a priori de los datos, y el no supervisado, caracterizado por la ausencia de conocimiento a priori.
Aprendizaje supervisado
Estos métodos son los más sencillos de realizar. En ellos se parte de un conocimiento a priori. El objetivo es, mediante unos datos de entrenamiento, deducir una función que haga lo mejor posible el mapeo entre unas entradas y una salida. Los datos de entrenamiento constan de tuplas \((X,Y)\), siendo \(X\) las variables que predicen una determinada salida \(Y\).
La variable a predecir \(Y\) puede ser una variable cuantitativa (como en el caso de problemas de regresión) o cualitativa (como en el caso de problemas de clasificación).
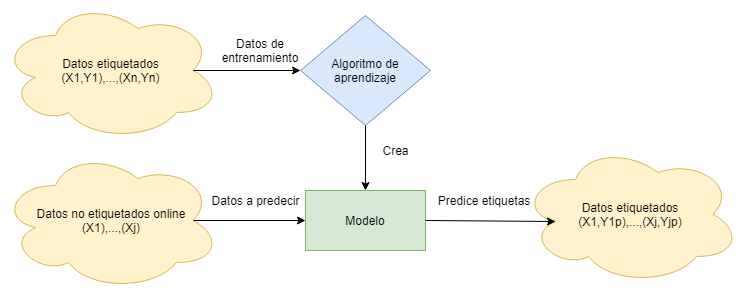
Esquema general de un modelo de aprendizaje supervisado
El objetivo del aprendizaje supervisado es obtener una función \(f\) desconocida dadas unas tuplas \((X,Y)=(X,f(X))\).
Se obtiene una estimación \((\hat{f})\) de la función \(f\), como aquella función que minimiza el riesgo empírico sobre el conjunto de entrenamiento.
La función del riesgo empírico tiene la siguiente fórmula:
$$R_{emp}(w)=\frac{1}{n}\sum L(y_i,\hat{f}(x_i,w))$$
siendo \(L\) una función de coste, \(w\) un conjunto de parámetros y \(x_i\) los datos de que predicen la variable \(y_i\).
Se aproxima la función f con \(\hat{f}\) tal que:
$$\hat{f}(x,w)=\underset{w \in \gamma}{arg\,min} R_{emp}(w)$$
Un ejemplo de función de coste en un problema de regresión es:
$$L(y,f(x,w))=(y-f(x,w))^2$$
Aprendizaje no supervisado
Al contrario que en el aprendizaje supervisado, en este caso no existe conocimiento a priori. Aquí ya no se tienen tuplas \((X,Y)\), simplemente se tienen \(X\).
El objetivo del aprendizaje no supervisado es modelizar la estructura o distribución de los datos para aprender más sobre ellos. Sirve tanto para entender como para resumir un conjunto de datos.
Se llama no supervisado porque, contrariamente al supervisado, tiende a ser más subjetivo ya que no tiene respuestas correctas. Los algoritmos sirven para descubrir y presentar estructuras interesantes en los datos.
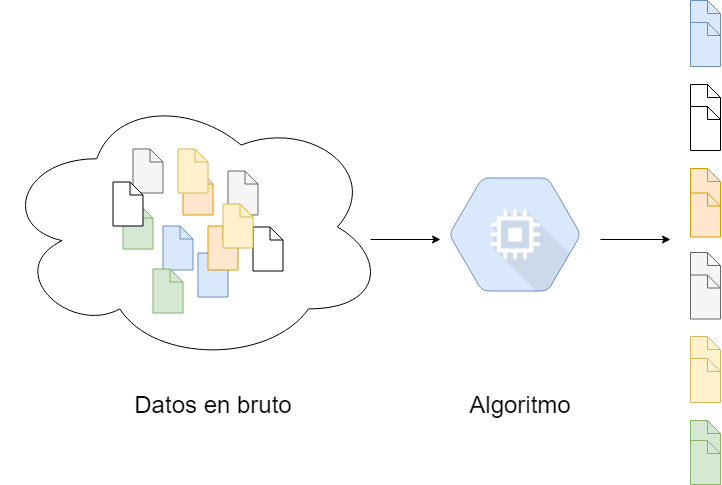
Esquema de un modelo de clustering o agrupamiento
En términos generales, pueden ser agrupados en algoritmos de clustering y algoritmos de asociación.
Aprendizaje semisupervisado
El aprendizaje semisupervisado se encuentra a medio camino entre el aprendizaje supervisado y el no supervisado.
Ahora lo que tenemos son tanto datos etiquetados como datos no etiquetados, es decir, además de tener tuplas \((X,Y)\), tenemos datos sólo de \(X\) de los que no sabemos su respuesta \(Y\).
El reto se encuentra en combinar datos etiquetados y no etiquetados para construir un modelo supervisado que sea mejor ya que:
- La cantidad de datos etiquetados se puede aumentar, lo que generalmente mejora los resultados de los modelos.
- Hay un alto coste de etiquetar los datos \(X\) sin etiquetas.
Supone que los datos etiquetados y no etiquetados provienen de la misma distribución. Por otro lado, puede existir un sesgo en la elección de datos no etiquetados.
Entre los métodos de aprendizaje semisupervisado se encuentran:
- Selft-training
- Co-training
- Assemble
- Re-Weighting
Aprendizaje por refuerzo
En los casos de aprendizaje supervisado se cuenta con tuplas \((X,y)\). Sin embargo, el caso de aprendizaje por refuerzo lo que tenemos son problemas no supervisados que sólo reciben re-alimentaciones o refuerzos (por ejemplo, gana o pierde).
Se sustituye la información supervisada \((Y)\) por información del tipo acción/reacción.
El objetivo en el aprendizaje por refuerzo es aprender a mapear situaciones de acciones para maximizar una cierta función de recompensa.
En estos problemas un agente aprende por prueba y error en un ambiente dinámico e incierto.
En cada interacción el agente recibe como entrada un indicador de estado actual y selecciona una determinada acción que maximice una función de refuerzo o recompensa a largo plazo.
Este proceso de decisión secuencial se puede caracterizar como un proceso de Markov.
Si te ha sido de utilidad este post, te agradecería que me apoyases en Patreon (donando una cantidad aunque sea poca ya sea una vez, o apoyándome mensualmente). Tener una web, dominio, hosting, no es gratis y me apoyas a seguir ayudando con la difusión de educación libre. Apóyame en Patreon! Mil gracias!!
¿Te ha parecido útil este artículo?

Hola buenas, me gustaría conocer de que fuentes tomaste esta información, gracias.
Hola Luis, la parte de riesgo empírico la saqué de la wikipedia. Mucho era ya sabido ya que llevo años y son conceptos que no se olvidan. Te dejo algunos links por si quieres echarle más tiempo, ya que este post es introductorio: https://en.wikipedia.org/wiki/Supervised_learning https://en.wikipedia.org/wiki/Unsupervised_learning https://blogs.nvidia.com/blog/2018/08/02/supervised-unsupervised-learning/ https://towardsdatascience.com/learning-theory-empirical-risk-minimization-d3573f90ff77 https://users.ece.utexas.edu/~dimakis/DataScience/Lecture1.pdf
Saludos, Álvaro