
¿Qué es el sobreajuste u overfitting y por qué debemos evitarlo?
25 mayo 2020En este post voy a tratar el tema del sobreajuste (en inglés overfitting) en los modelos de aprendizaje automático. Es muy común que los científicos de datos, sobre todo los que están empezando y no tienen mucha experiencia, entrenen modelos y obtengan una métrica en entrenamiento que ellos creen que es muy buena. Luego, a la hora de predecir datos nuevos, el modelo se comporta mucho peor que en entrenamiento. Esto es un problema muy importante al productivizar modelos, ya que modelos que en desarrollo parecían buenos, en productivización son una hecatombe. Esto se debe muchas veces al hecho de que esos modelos están sobreajustados a los datos de entrenamiento.
Concepto de sobreajuste
Este concepto es uno de los conceptos clave en aprendizaje automático. Se denomina sobreajuste al hecho de hacer un modelo tan ajustado a los datos de entrenamiento que haga que no generalice bien a los datos de test.
Hay que recordar que el objetivo de los modelos de aprendizaje automático es el de obtener patrones de los datos de entrenamiento disponibles de cara a predecir o inferir correctamente datos nuevos. Es decir, el concepto clave es el de entrenar y obtener patrones generales que sean extrapolables a nuevos datos. Algo similar ocurre en el aprendizaje de los seres humanos, el sobreajuste se produciría cuando aprendemos las cosas de memoria, sin entender el concepto.
Cuándo se produce el sobreajuste
El sobreajuste se produce cuando un sistema de aprendizaje automático se entrena demasiado o con datos anómalos, que hace que el algoritmo «aprenda» patrones que no son generales. Aprende características especificas pero no los patrones generales, el concepto. Los modelos más complejos tienden a sobreajustar más que lo modelos más simples. Además, ante un mismo modelo, a menor cantidad de datos es más posible que ese modelo se sobreajuste.
¿Cómo evaluarlo?
Existen varios métodos para evaluar cuándo un modelo está sobreajustando. Uno de los métodos es por medio de las gráficas de errores de entrenamiento y de test. Se pueden representar las gráficas de error del modelo en los datos usados para entrenar (Train) y en los datos usados para validar el modelo (Test). Lo ideal es que ambos errores estén lo más cerca posible. En la siguiente representación os muestro el error en Train (azul) y en Test (rojo) a medida que aumenta la complejidad del modelo. Es decir, a medida que aumenta la capacidad de captar detalles, el error en Train se reduce, pero llega un punto en el que el modelo empieza a «memorizar» patrones no generales y empieza a aumentar el error en Test.
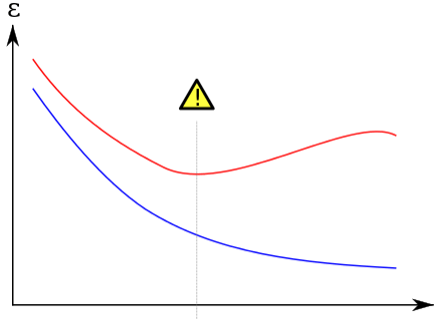
En rojo el error en test, en azul el error en train a medida que aumenta la complejidad del modelo
¿Cómo evitar el sobreajuste?
El sobreajuste se puede evitar de varias formas, las más claras son las siguientes:
- Incorporando mayor cantidad de datos: al tener más cantidad de datos es más probable que el algoritmo generalice mejor, al tener en cuenta más tipos de datos.
- Cambiando los parámetros de ciertos algoritmos, haciendo los algoritmos más simples: haciendo que el algoritmo sea más simple, se ajusta menos a los datos y es menos posible sobreajustar a los datos de entrenamiento. Por ejemplo, reduciendo la profundidad de un árbol de decisión se ajusta menos al hacer el modelo más simple.
- Incorporando regularización: existen parámetros en muchos algoritmos que permiten regularizar los parámetros, evitando en cierta medida el sobreajuste. Comúnmente hay dos tipos, que son la L1 y la L2. En este enlace tenéis este concepto con una explicación más detallada.
Espero que os haya sido útil este artículo para entender la importancia de realizar modelos que generalicen bien a nuevos datos, evitando así el sobreajuste a los datos de entrenamiento.
Saludos 🙂
Si te ha sido de utilidad este post, te agradecería que me apoyases en Patreon (donando una cantidad aunque sea poca ya sea una vez, o apoyándome mensualmente). Tener una web, dominio, hosting, no es gratis y me apoyas a seguir ayudando con la difusión de educación libre. Apóyame en Patreon! Mil gracias!!
¿Te ha parecido útil este artículo?

Hola Alvaro, me gusto la definición que nos estás ayudando a compartir sobre el concepto del Overfitting. Buen trabajo.
Muy bien Álvaro. Sería muy bueno ver algún ejemplo de un problema que hayas resuelto aplicando regularización para evitar el sobreajuste. O si tienes algún link interesante de este punto sería estupendo compartirlo. Gracias!
Muchas gracias por tu comentario Adriana!
Acabo de poner un enlace a una web donde creo que se explica bastante bien. Fijarse sobre todo en las gráficas de errores en Test función de la regularización. Al principio se reduce el error en Test (evitamos sobreajustar y generalizamos bien) y posteriormente, cuando la regularización es muy grande el error aumenta (no sólo no sobreajustamos sino que infrajustamos por aumentar tanto la regularización).
Álvaro