
¿Cuál es la diferencia entre los métodos de bagging y los de boosting?
24 febrero 2020Los algoritmos consistentes en la combinación de algoritmos simples usando bagging y boosting son muy populares en Machine Learning. En competiciones online como Kaggle son de los que han demostrado ofrecer mejores resultados. Entre los métodos de aprendizaje automático más usados se encuentran el XGBoost, el Random Forest o el AdaBoost. Todos estos algoritmos de aprendizaje automático tienen algo en común, son algoritmos que se denominan ensamblados.
¿En qué consisten los algoritmos ensamblados? De manera sencilla podría decirse que son algoritmos formados por algoritmos más simples. Estos algoritmos simples se unen para formar un algoritmo más potente. Como bien dicen «La unión hace la fuerza«, y lo demuestran los algoritmos ensamblados.
Aunque hay diversas formas de ensamblar o unir algoritmos débiles para formar otros, las más usadas y populares son el bagging y el boosting (aunque existen otras como el stacking). Cada tipo de algoritmo tiene unas ventajas y unos inconvenientes y pueden ser usados convenientemente según nuestra problemática.
Algoritmos de bagging:
Aunque de primeras esta clase de algoritmo no te suene tanto, a lo mejor te suena el algoritmo Random Forest. Este algoritmo es un ejemplo de uso de bagging que combina árboles de decisión para formar el Random Forest.
«El principal objetivo intrínseco de los algoritmos de bagging es el de la reducción de la varianza»
Los métodos de bagging son métodos donde los algoritmos simples son usados en paralelo. El principal objetivo de los métodos en paralelo es el de aprovecharse de la independencia que hay entre los algoritmos simples, ya que el error se puede reducir bastante al promediar las salidas de los modelos simples. Es como si, queriendo resolver un problema entre varias personas independientes unas de otras, damos por bueno lo que eligiese la mayoría de las personas.
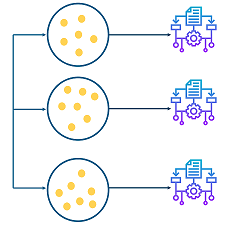
Métodos paralelos de bagging
Bagging proviene del concepto de agregación de bootstrap. Un forma de reducir la varianza de las estimaciones es promediando estimaciones de distintos modelos o algoritmos.
Para obtener la agregación de las salidas de cada modelo simple e independiente, bagging puede usar la votación para los métodos de clasificiación y el promedio para los métodos de regresión.
Algoritmos de boosting:
Por otro lado, dentro de los algoritmos ensamblados tenemos los algoritmos de boosting. Algunos ejemplos de estos algoritmos son el XGBoost o el AdaBoost.
«El principal objetivo de los algoritmos de boosting es el de la reducción del sesgo»
En los algoritmos de boosting, los modelos simples son utilizados secuencialmente, es decir, cada modelo simple va delante o detrás de otro modelo simple. El principal objetivo de los métodos secuenciales es el de aprovecharse de la dependencia entre los modelos simples. El rendimiento general puede ser mejorado haciendo que un modelo simple posterior le de más importancia a los errores cometidos por un modelo simple previo. Poniendo un ejemplo, es como si nosotros al resolver un problema aprovechásemos nuestro conocimiento de los errores de otros para mejorar en algo intentando no cometerlos nosotros.
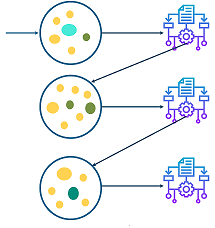
Métodos secuenciales de boosting
Las predicciones de cada modelo simple se combinan por medio de una votación (para problemas de clasificación) o por medio de una suma ponderada (para problemas de regresión) para producir la predicción final. La diferencia con el bagging es que en el boosting los algoritmos no se entrenan independientemente, sino que se ponderan según los errores de los anteriores.
Hasta aquí las diferencias entre los métodos de bagging y de boosting.
Si tienes alguna duda, no te ha quedado claro algún concepto o quieres compartir cualquier cosa déjanos un comentario. Saludos! 🙂
Si te ha sido de utilidad este post, te agradecería que me apoyases en Patreon (donando una cantidad aunque sea poca ya sea una vez, o apoyándome mensualmente). Tener una web, dominio, hosting, no es gratis y me apoyas a seguir ayudando con la difusión de educación libre. Apóyame en Patreon! Mil gracias!!
¿Te ha parecido útil este artículo?

Gracias!! por fin entendí el bagging
Buen resumen en castellano. Gracias