![Mejores másteres de data science, inteligencia artificial y big data [2023]](https://machinelearningparatodos.com/wp-content/uploads/2019/07/graduation-1024x641.jpg "Mejores másteres de data science, inteligencia artificial y big data [2023]")
10 septiembre 2023
Mejores másteres de data science, inteligencia artificial y big data [2023]

24 julio 2023
¿Qué es R y para qué utilizarlo?

17 julio 2023
Big Data, ¿qué es y cómo funciona?
 Segmentación utilizando K-means en PythonLa segmentación con técnicas estadísticas es muy usada en diversos problemas. En marketing son útiles los modelos estadísticos para segmentar o dividir poblaciones en grupos distintos. Esto permite realizar campañas diferentes a cada uno de los grupos. Los modelos estadísticos de segmentación también son empleados en procesamiento de imágenes así como en algoritmos de compresión de… Leer más
Segmentación utilizando K-means en PythonLa segmentación con técnicas estadísticas es muy usada en diversos problemas. En marketing son útiles los modelos estadísticos para segmentar o dividir poblaciones en grupos distintos. Esto permite realizar campañas diferentes a cada uno de los grupos. Los modelos estadísticos de segmentación también son empleados en procesamiento de imágenes así como en algoritmos de compresión de… Leer más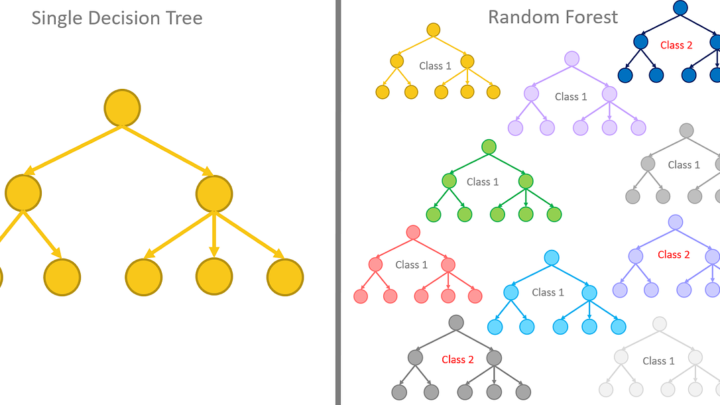 Árboles de decisión en PythonEn el campo del machine learning, los árboles de decisión son un algoritmo ampliamente utilizado para la clasificación y regresión de datos. Son modelos predictivos que utilizan una estructura similar a un árbol para tomar decisiones basadas en características o atributos de los datos de entrada. En este artículo, exploraremos en detalle cómo funcionan los… Leer más
Árboles de decisión en PythonEn el campo del machine learning, los árboles de decisión son un algoritmo ampliamente utilizado para la clasificación y regresión de datos. Son modelos predictivos que utilizan una estructura similar a un árbol para tomar decisiones basadas en características o atributos de los datos de entrada. En este artículo, exploraremos en detalle cómo funcionan los… Leer más Problemas comunes en aprendizaje automáticoDespués de hablar de qué es el aprendizaje automático, es bueno hacerse una idea de los tipos de problemas más típicos que se presentan en el campo de la ciencia de datos. Saber identificar nuestro problema es ciertamente útil ya que de esa forma podremos saber cómo abordarlo y qué técnicas y algoritmos usar para… Leer más
Problemas comunes en aprendizaje automáticoDespués de hablar de qué es el aprendizaje automático, es bueno hacerse una idea de los tipos de problemas más típicos que se presentan en el campo de la ciencia de datos. Saber identificar nuestro problema es ciertamente útil ya que de esa forma podremos saber cómo abordarlo y qué técnicas y algoritmos usar para… Leer más Mejores másteres de España para aprender data science y Big DataEn mi experiencia como científico de datos me han preguntado muchas veces «¿Qué másteres me recomendarías para aprender data science?». La respuesta que doy a esa pregunta suele ser siempre «Depende de lo que busques». En España hay másteres de distintos precios y tipos, por lo que creo que lo primero es saber cuál es… Leer más
Mejores másteres de España para aprender data science y Big DataEn mi experiencia como científico de datos me han preguntado muchas veces «¿Qué másteres me recomendarías para aprender data science?». La respuesta que doy a esa pregunta suele ser siempre «Depende de lo que busques». En España hay másteres de distintos precios y tipos, por lo que creo que lo primero es saber cuál es… Leer más


¿Qué es el aprendizaje automático o machine learning?
30 abril 2018
Aprender ciencia de datos por tu cuenta
8 abril 2019




Últimos comentarios