![Mejores másteres de data science, inteligencia artificial y big data [2023]](https://machinelearningparatodos.com/wp-content/uploads/2019/07/graduation-1024x641.jpg "Mejores másteres de data science, inteligencia artificial y big data [2023]")
10 septiembre 2023
Mejores másteres de data science, inteligencia artificial y big data [2023]

24 julio 2023
¿Qué es R y para qué utilizarlo?

17 julio 2023
Big Data, ¿qué es y cómo funciona?
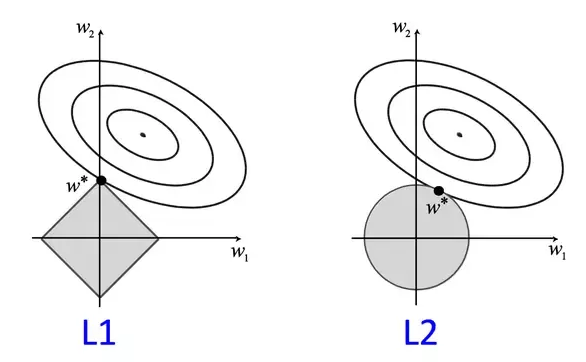 Regularización en Machine Learning. Ejemplo con PythonLa regularización es una técnica utilizada en machine learning para evitar el sobreajuste (overfitting) de los modelos. El sobreajuste ocurre cuando un modelo se ajusta demasiado a los datos de entrenamiento y pierde la capacidad de generalizar para nuevos datos. Regularizar los modelos nos ayuda a reducir la complejidad del modelo y a evitar el… Leer más
Regularización en Machine Learning. Ejemplo con PythonLa regularización es una técnica utilizada en machine learning para evitar el sobreajuste (overfitting) de los modelos. El sobreajuste ocurre cuando un modelo se ajusta demasiado a los datos de entrenamiento y pierde la capacidad de generalizar para nuevos datos. Regularizar los modelos nos ayuda a reducir la complejidad del modelo y a evitar el… Leer más- ¿Qué es R y para qué utilizarlo?R es un lenguaje de programación ampliamente utilizado en el ámbito del análisis de datos y la estadística. Es un entorno de software de código abierto y gratuito que ofrece una amplia gama de herramientas y bibliotecas especializadas para el procesamiento, la visualización y el modelado de datos. En este artículo, exploraremos qué es R… Leer más
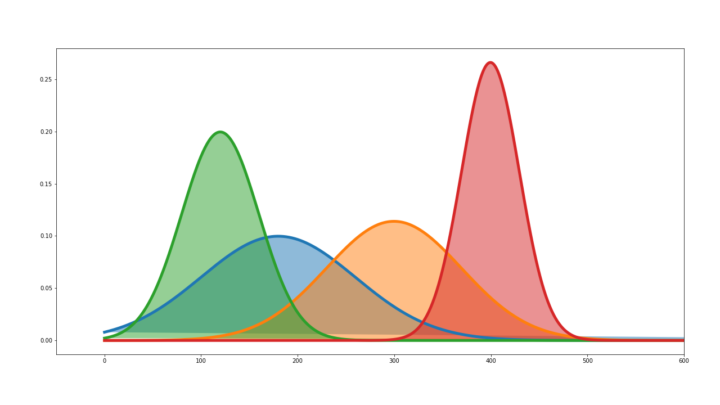 ¿Cómo saber si una variable sigue una distribución normal en Python?Saber si una variable sigue una distribución normal o no es muy importante en ciertos problemas de ciencia de datos y aprendizaje automático. Existen ciertos tests que nos permiten comprobar si una distribución sigue una forma normal o Gaussiana. Funciones de distribución Primero de todo quiero definir lo que es una función de distribución, para… Leer más
¿Cómo saber si una variable sigue una distribución normal en Python?Saber si una variable sigue una distribución normal o no es muy importante en ciertos problemas de ciencia de datos y aprendizaje automático. Existen ciertos tests que nos permiten comprobar si una distribución sigue una forma normal o Gaussiana. Funciones de distribución Primero de todo quiero definir lo que es una función de distribución, para… Leer más ¿Cuál es la diferencia entre los métodos de bagging y los de boosting?Los algoritmos consistentes en la combinación de algoritmos simples usando bagging y boosting son muy populares en Machine Learning. En competiciones online como Kaggle son de los que han demostrado ofrecer mejores resultados. Entre los métodos de aprendizaje automático más usados se encuentran el XGBoost, el Random Forest o el AdaBoost. Todos estos algoritmos de aprendizaje… Leer más
¿Cuál es la diferencia entre los métodos de bagging y los de boosting?Los algoritmos consistentes en la combinación de algoritmos simples usando bagging y boosting son muy populares en Machine Learning. En competiciones online como Kaggle son de los que han demostrado ofrecer mejores resultados. Entre los métodos de aprendizaje automático más usados se encuentran el XGBoost, el Random Forest o el AdaBoost. Todos estos algoritmos de aprendizaje… Leer más


¿Qué es el aprendizaje automático o machine learning?
30 abril 2018
Aprender ciencia de datos por tu cuenta
8 abril 2019




Últimos comentarios